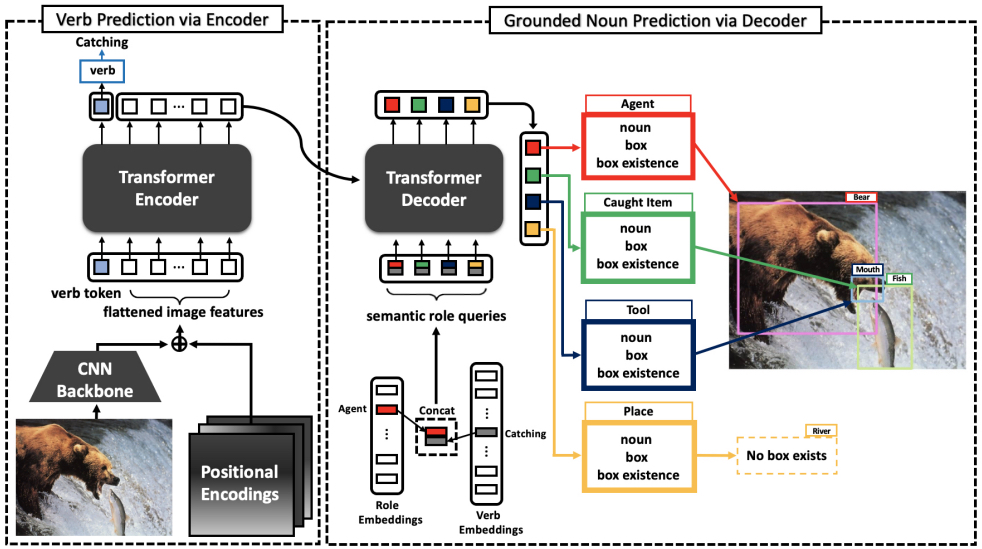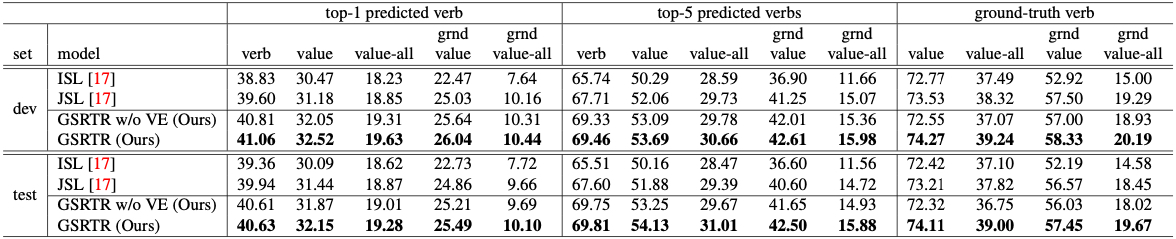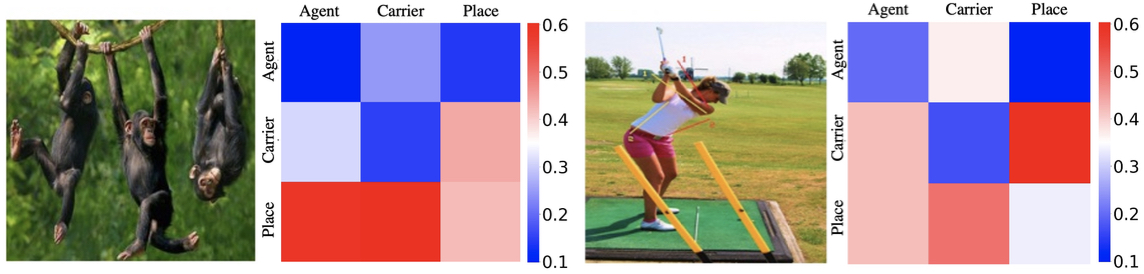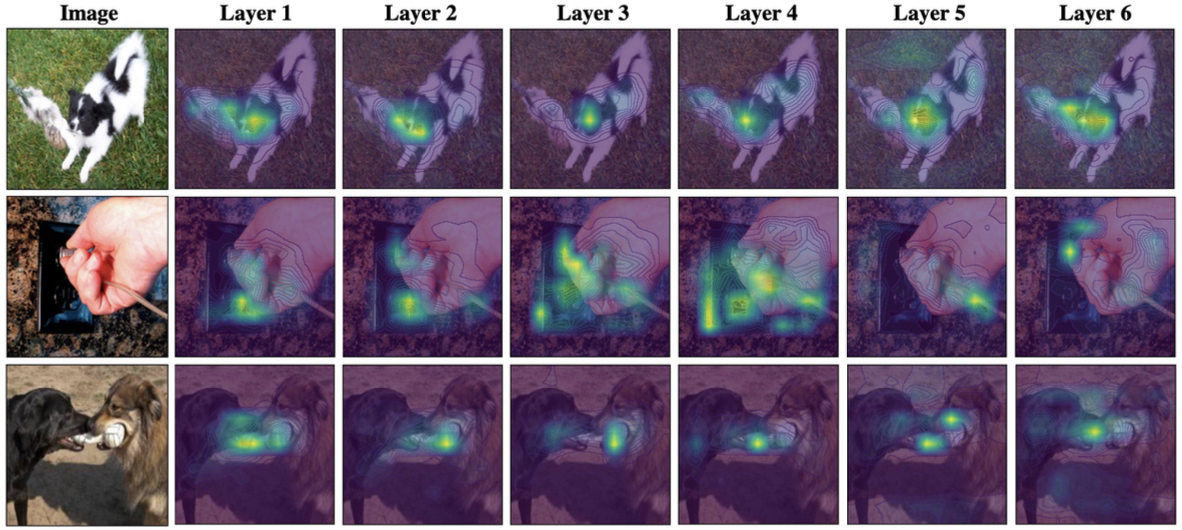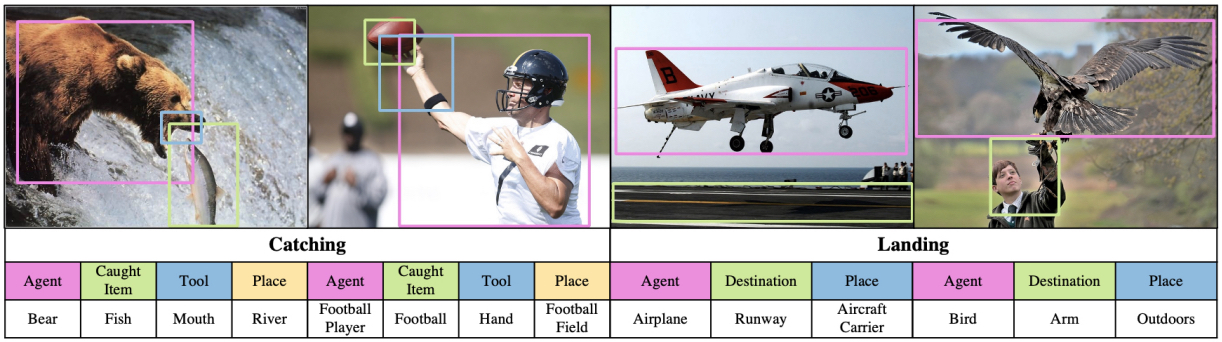
Grounded Situation Recognition (GSR) is the task that not only classifies a salient action (verb), but also predicts entities (nouns) associated with semantic roles and their locations in the given image. Inspired by the remarkable success of Transformers in vision tasks, we propose a GSR model based on a Transformer encoder-decoder architecture. The attention mechanism of our model enables accurate verb classification by capturing high-level semantic feature of an image effectively, and allows the model to flexibly deal with the complicated and image-dependent relations between entities for improved noun classification and localization. Our model is the first Transformer architecture for GSR, and achieves the state of the art in every evaluation metric on the SWiG benchmark.
@InProceedings{cho2021GSRTR,
title={Grounded Situation Recognition with Transformers},
author={Junhyeong Cho and Youngseok Yoon and Hyeonjun Lee and Suha Kwak},
booktitle={British Machine Vision Conference (BMVC)},
year={2021}
}